BMV: Behavioral Model of Visual Perception and Recognition
I. A. Rybak, V. I. Gusakova, A. V. Golovan, L. N. Podladchikova, and N. A. Shevtsova
A. B. Kogan Research Institute for Neurocybernetics, Rostov State University, Rostov-on-Don, Russia
The mind can only see what it is prepared to see.
Edward de Bono
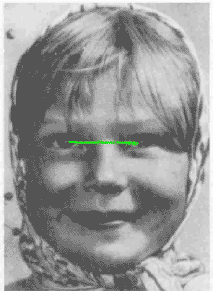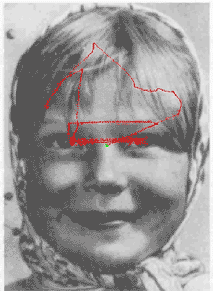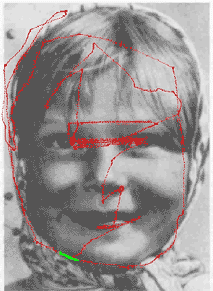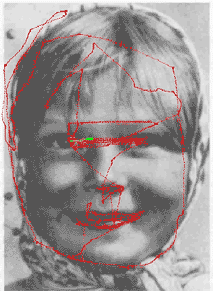
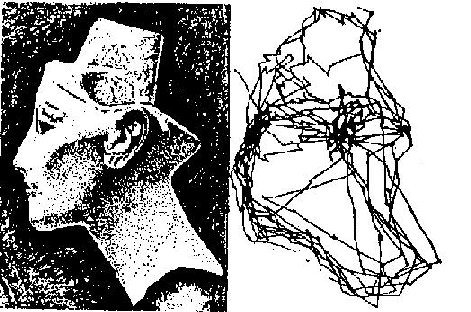
This animated Yarbus' figure is taken from the page of Dr. Albert Fuchs (U. Washington).
Approach
During visual perception and recognition, human eyes move and successively fixate at the most informative parts of the image (Yarbus 1967, see illustrations above and on the right). The eyes actively perform problem-oriented selection and processing of information from the visible world under the control of visual attention (Burt 1988; Julesz 1975; Neisser 1967; Noton and Stark 1971; Triesman and Gedal 1980, Yarbus 1967). Consequently, visual perception and recognition may be considered as behavioral processes, and probably cannot be completely understood in limited frames of neural computations without taking into account behavioral and cognitive aspects of these processes.
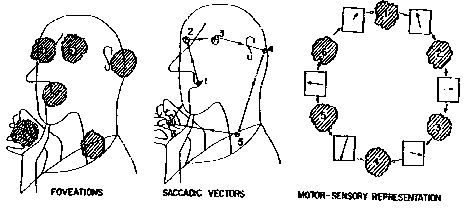
From the behavioral point of view, an internal representation (model) of new circumstances is formed in the brain during conscious observation and active examination. The active examination is aimed toward the finding and memorizing of functional relationships between the applied actions and the resulting changes in sensory information. An external object becomes "known" and may be recognized when the system is able to subconsciously manipulate the object and to predict the object's reactions to the applied actions. According to this paradigm, the internal object representation contains chains of alternating traces in "motor" and "sensory" memories. Each of these chains reflects an alternating sequence of elementary motor actions and sensory (proprioceptive and external) signals which are expected to arrive in response to each action. The brain uses these chains as "behavioral programs" in subconscious "behavioral recognition" when the object is (or is assumed) known.
This "behavioral recognition" has two basic stages: (i) conscious selection of the appropriate behavioral program (when the system accepts a hypothesis about the object), and (ii) subconscious execution of the program. Matching the expected (predicted) sensory signals to the actual sensory signals, arriving after each motor action, is an essential operation in the program execution.
The above behavioral paradigm was formulated and developed in the context of visual perception and recognition in a series of significant works (Yarbus, 1967; Noton & Stark, 1971; Didday & Arbib, 1975; Kosslyn et al., 1990; Rimey and Brown, 1991). Using Yarbus' approach, Noton and Stark (1971) compared the individual scanpaths of human eye movements in two phases: during image memorizing, and during the subsequent recognition of the same image. They found these scanpaths to be topologically similar and suggested that each object is memorized and stored in memory as an alternating sequence of object features and eye movements required to reach the next feature. The results of Noton and Stark (1971) and Didday and Arbib (1975) prompted the consideration of eye movement scanpaths as behavioral programs for recognition. The process of recognition was supposed to consist of an alternating sequence of eye movements (recalled from the motor memory and directed by attention) and verifications of the expected image fragments (recalled from the sensory memory).
Ungerleider and Mishkin (1982), Mishkin, Ungerleider and Macko (1983), Van Essen (1985), and Kosslyn et al. (1990) presented neuro-anatomical and psychological data complementary to the above behavioral concept. It was found that the higher levels of the visual system contain two major pathways for visual processing called "where" and "what" pathways. The "where" pathway leads dorsally to the parietal cortex and is involved in processing and representing spatial information (spatial locations and relationships). The "what" pathway leads ventrally to the inferior temporal cortex and deals with processing and representing object features.
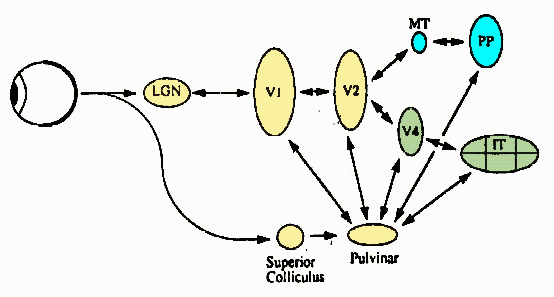
Our approach is based on the above behavioral, psychological and anatomical concepts. We propose that invariant object recognition in human vision is provided by the following:
(i) separated processing and representation of "what" (object features) and "where" (spatial features: elementary eye movements) information at the high levels of the visual system
(ii) using a frame of reference attached to the "basic" feature at each fixation point for the invariant encoding of "what" and "where" pieces of information, i.e., a feature-based frame of reference
(iii) testing a hypothesis formed at single fixation during a series of consequent fixations under top-down control of attention
(iv) mechanisms of visual attention that use "where" information stored in the memory to direct sequential image processing (hypothesis testing)
(v) mechanisms which provide matching the current object features to the expected features ( "what" information stored in the memory) at each fixation
Model
A functional diagram of the model is shown in Figure 1 (see below). The attention window (AW) performs a primary transformation of the image into a "retinal image" at the fixation point. The primary transformation provides a decrease in resolution of the retinal image from the center to the periphery of the AW that simulates the decrease in resolution from the fovea to the retinal periphery in the cortical map of the retina. An example of the "retinal image" is shown in Figure 2.

The test image (left), and the retinal image within the attention window at one fixation point (marked by cross) on background of the test image (right).
The retinal image in the AW is used as input to the module for primary feature detection which performs a function similar to the primary visual cortex. This module contains a set of neurons with orientationally selective receptive fields (ORF) tuned to different orientations of the local edge. Neurons with the ORF, centered at the same point but with different orientation tuning, interact competitively due to strong reciprocal inhibitory interconnections. The orientation tuning of the "winning neuron" encodes the edge orientation at each point. In each fixation (AW position), the module for primary feature detection extracts a set of edges. This set includes a "basic" edge located at the fixation point (center of AW) and several "context" edges located at specific positions in the retinal image. Thus, the module for primary feature encoding represents the image fragment at the current fixation point by the set of oriented edges extracted with resolution decreased to the periphery of AW. (An example is shown in Figure 3).

The retinal image (left), and primary features (edges) detected in the attention window (right). The basic (in the AW center) and context edges are shown by doubled white and black segments whose length increases to the AW periphery with the decrease of resolution.
The modules described above form a low-level subsystem of the model. The next module performs a mid-level processing. It transforms the set of primary features into the invariant second-order features using a coordinate system (frame of reference) attached to the basic edge in the center of the AW and oriented along the brightness gradient of the basic edge. The relative orientations and relative angular locations of the context edges with respect to the basic edge are considered as invariant second-order features.
The performance of the high-level subsystem and the entire model may be considered in three different modes: memorizing, search and recognition.

The next fixation point is selected from the set of context points in the current retinal image. The current and next fixation points are marked by crosses (right). Shift to the next fixation point is shown by the black arrow (right).
In the memorizing mode, the image is processed at sequentially selected fixation points. At each fixation point, the set of edges is extracted from the AW, transformed into the invariant second-order features and stored in the sensory memory ("what" structure). The next position of the AW (next fixation point) is selected from the set of context points (see an example in Figure 4) and is represented in the coordinate system attached to the basic edge. A special module shifts the AW to a new fixation point via the AW controller playing the role of the oculomotor system. Each relative shift of the AW ("eye movement") is stored in the motor memory ("where"-structure).


Illustrations of parallel-sequential image processing during the memorizing and recognition modes.
See Figure 5 for an example of the scanpath of viewing during the memorizing mode. As a result of the memorizing mode, the whole sequence of retinal images is stored in the "what" structure (sensory memory), and the sequence of AW movements is stored in the "where" structure (motor memory). These two types of elementary "memory traces" alternate in a chain which is considered as a "behavioral recognition program" for the memorized image.

The scanpath of image viewing is shown on background of the initial image (left) and on background of the sequence of retinal images along the scanpath (right).
In the search mode, the image is scanned by the AW under the control of a search algorithm. At each fixation, the current retinal image from the AW is compared to all retinal images of all objects stored in the sensory memory. The scanning of the image continues until a retinal image similar to one of the stored retinal images is found at some fixation point. When such a retinal image is found, a hypothesis about the image is formed, and the model turns to the recognition mode.
In the recognition mode, the behavioral program is executed by consecutive shifts of the AW (controlled by the AW controller using data recalled from the motor memory) and consecutive verification of the expected retinal images recalled from the sensory memory. The scanpath of viewing in the recognition mode reproduces sequentially the scanpath of viewing in the memorizing mode. If a series of successful matches occurs, the object is recognized, otherwise the model returns to the search mode.
Our simulation showed that the model can recognize complex gray-level images (e.g., faces) invariantly with respect to shift, rotation and scale. Click below to see examples of invariant recognition of scene objects and faces.
Publications
"A model of attention-guided visual perception and recognition" [PDF]
Rybak, I. A., Gusakova, V. I., Golovan, A. V., Podladchikova, L. N., and Shevtsova, N. A.
Vision Research 38: 2387-2400 (1998)
"Attention-guided recognition based on “what” and “where” representations: A behavioral model" [available upon request]
Rybak, I. A., Gusakova, V. I., Golovan, A. V., Podladchikova, L. N., and Shevtsova, N. A.
In: Neurobiology of Attention (Eds. Itti, L., Rees, G. and Tsotsos, J.). Elsevier Acad. Press, pp. 663-670 (2005)

In memory of Professor Lawrence Stark
Contact Us
The Laboratory for Theoretical and Computational Neuroscience
Department of Neurobiology and Anatomy
Drexel University College of Medicine
2900 W. Queen Lane
Philadelphia, PA 19129
rybak@drexel.edu
Back to Top